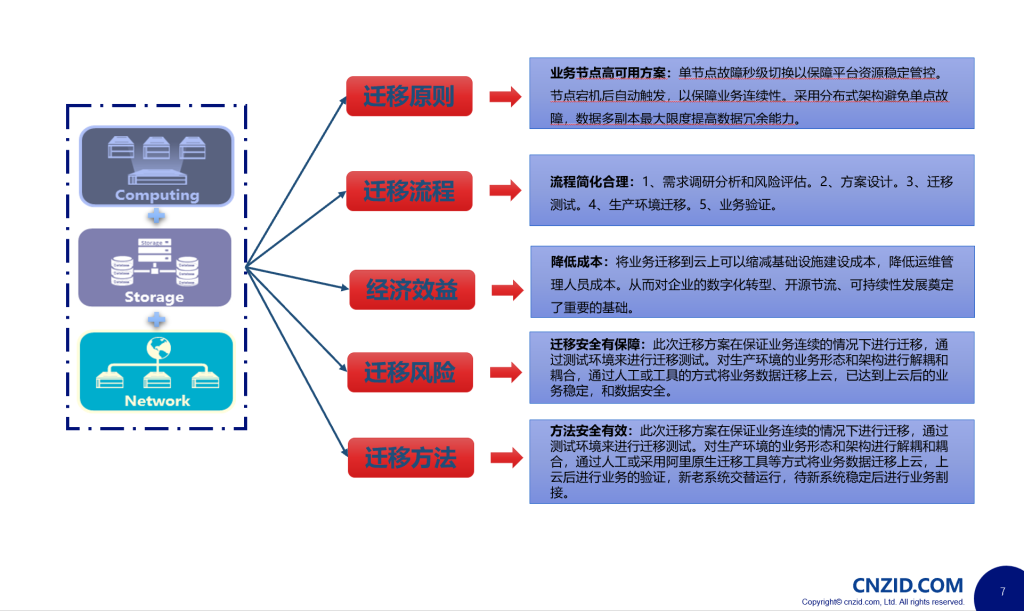
评估分析流程
我是钱锅锅,我无所畏惧,我一生渴望被收藏好,妥善安放,细心保存。免我惊,免我苦,免我四下流离,免我无枝可依。
评估分析流程
“https://docker.m.daocloud.io”,
“https://noohub.ru”,
“https://huecker.io”,
“https://dockerhub.timeweb.cloud”
启用嵌套VT-x/AMD-V”功能变灰问题>>>(主机硬件必须要支持Intel VT-x或AMD-V虚拟化技术,并在BIOS设置打开)
0.打开VirtualBox本体文件所在的位置,搜索栏输入cmd回车
1.输入【VBoxManage.exe list vms】,回车
2.输入【VBoxManage.exe modifyvm “改成虚拟机名字” –nested-hw-virt on】(on改off,则为关闭),回车
給大家推荐一个通过gpu对视频文件进行压缩处理的程序,压缩后的视频在画质上基本无损。(用肉眼看基本上看不出差别)
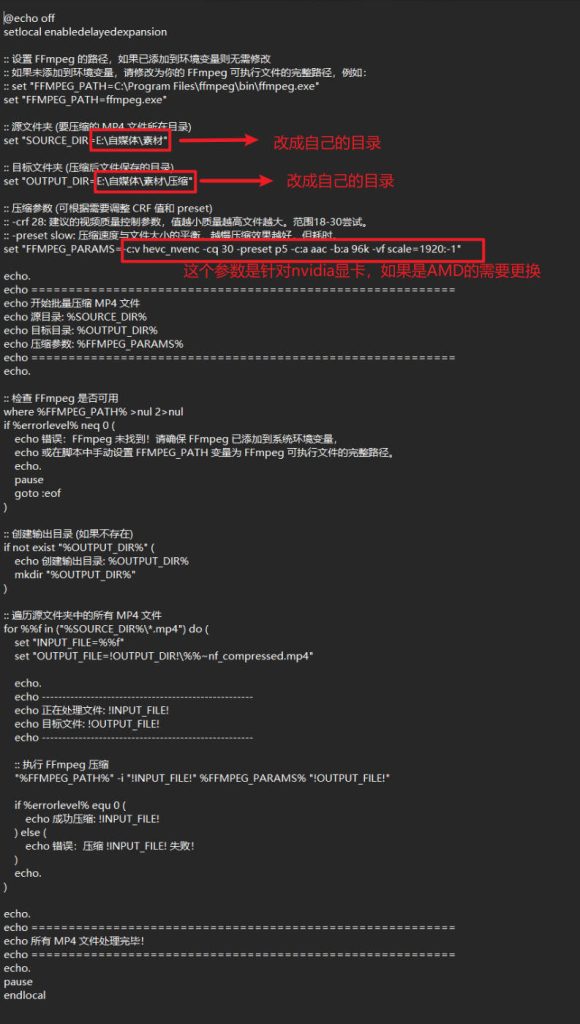
下载地址如下:
通过网盘分享的文件:视频压缩程序文件.rar
链接: https://pan.baidu.com/s/1POLZgVYlzL4F2nvxtYd2rg 提取码: kux4
CloudStack遇到数据库增长的问题,可能的原因有哪些呢?可能是日志数据过多,或者配置了过多的历史记录,比如虚拟机操作日志、事件日志、使用量数据等。另外,可能有一些未清理的旧数据,比如删除的虚拟机、卷、快照等残留的记录。还有可能是数据库本身的表碎片过多,导致空间占用大,当数据增长到一定程度后会导致云平台操作超时无法打开。
总结一下,处理步骤可能包括:
1. 清理旧数据和日志。
2. 调整CloudStack的清理参数。
3. 优化数据库表。
4. 使用分区表。
5. 归档和备份策略。
6. 调整配置参数。
7. 升级版本。
8. 监控和维护。
针对CloudStack数据库不断增大的问题,以下是分步解决方案及详细说明:
CloudStack默认会保留历史数据,需检查自动清理配置是否合理。
-- 修改事件保留天数(默认30天)
UPDATE `cloud`.`configuration` SET value='7' WHERE name='event.purge.delay';
-- 修改使用量统计保留天数(默认180天)
UPDATE `cloud`.`configuration` SET value='30' WHERE name='usage.stats.job.retention.time';
-- 调整清理任务间隔(默认86400秒=1天)
UPDATE `cloud`.`configuration` SET value='86400' WHERE name='event.purge.interval'; # 登录CloudStack管理节点
cloudstack-management purge-old-events -d 7 # 清理7天前事件
cloudstack-management purge-usage -d 30 # 清理30天前使用量数据若无需计费功能,可关闭使用量统计。
UPDATE `cloud`.`configuration` SET value='false' WHERE name='usage.stats.job.enable'; UPDATE `cloud`.`configuration` SET value='1800' WHERE name='usage.stats.job.interval';针对碎片化严重的表进行优化。
OPTIMIZE TABLE cloud_usage.usage_volume;
OPTIMIZE TABLE cloud_usage.usage_event;
OPTIMIZE TABLE cloud.op_nwgrp_work;注:InnoDB引擎建议改用ALTER TABLE <表名> ENGINE=InnoDB;,避免全表锁问题。
pt-online-schema-change --alter "ENGINE=InnoDB" D=cloud_usage,t=usage_volume --execute按时间分区,快速删除旧数据。
cloud_usage.usage_event表): ALTER TABLE usage_event
PARTITION BY RANGE (TO_DAYS(created)) (
PARTITION p202301 VALUES LESS THAN (TO_DAYS('2023-02-01')),
PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01')),
PARTITION p_max VALUES LESS THAN MAXVALUE
); ALTER TABLE usage_event DROP PARTITION p202301;减少非必要日志量。
log4j2.xml): <Logger name="com.cloud" level="info" additivity="false">
<Logger name="org.apache.cloudstack" level="warn" /> find /var/log/cloudstack/ -name "*.log*" -mtime +7 -delete分离历史数据并压缩备份。
CREATE TABLE cloud_usage.usage_event_archive LIKE cloud_usage.usage_event;
INSERT INTO cloud_usage.usage_event_archive
SELECT * FROM cloud_usage.usage_event WHERE created < '2023-01-01';
DELETE FROM cloud_usage.usage_event WHERE created < '2023-01-01'; mysqldump -u root -p --single-transaction --quick cloud | gzip > cloud_backup.sql.gz新版可能优化数据管理,如CloudStack 4.18+改进事件清理逻辑。
#!/bin/bash
mysql -u cloud -p密码 -e "DELETE FROM cloud_usage.usage_event WHERE created < NOW() - INTERVAL 90 DAY;"
mysqlcheck -o cloud_usage usage_eventmysqldump -u root -p --databases cloud cloud_usage > backup.sql通过上述步骤,可有效控制数据库增长,提升CloudStack性能。
当云服务器后端使用的是rbd方式对接云平台时,有时会遇到宿主机意外断电,停机或重启故障后,VM会报超级块(superblock)的问题导致VM的系统无法正常启动的处理办法:
原因:由于主机突然断电导致RBD锁住,VM无法启动,需要解锁。Ceph RBD的锁机制。当使用exclusive-lock特性时,RBD镜像会被客户端锁定,防止多个客户端同时写入导致数据损坏。突然断电可能导致锁未被正确释放,所以VM无法启动,因为锁仍然存在。
解决方法:
#查看镜像的锁信息(需指定池和镜像名称)
rbd lock ls <pool>/<image>
# 强制删除锁(需指定锁的ID)
rbd lock remove <pool>/<image> <lock-id> <client-id>
#实例:
rbd lock ls hdd_pool_01/abad99f9-50dd-4c8d-b595-0ff7f50cfa4d988
rbd lock remove hdd_pool_01/abad99f9-50dd-4c8d-b595-0ff7f50cfa4d "auto 94778552067968" client.1264649449
愿你以代码为剑,服务器为盾,勇闯运维江湖,克服每一个挑战,驾驭每一行命令。即便遇到故障如山,也能以日志为钥,脚本为桥,突破重围,重启梦想,成就不败架构!
曾照晴窗云影深
斯人眉底有星辰
涵香砚底春冰裂
一笔东风破墨痕
蛇年伊始,祝我的朋友们不慌不忙,心之所向,行之所往,终至所归,一路向阳,新年快乐!

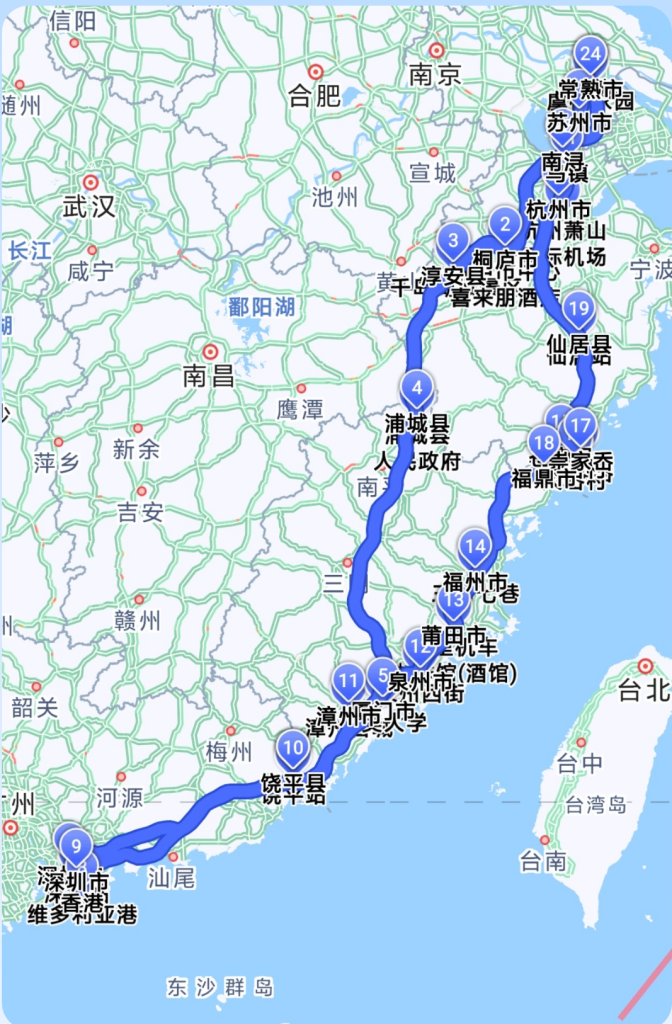
15天,跨越4000多公里,一头扎进六地的万种风情。从江苏的温婉,到浙江的灵秀,再历经江西的壮阔、福建的古朴、广东的活力,最后在香港感受国际都市的魅力,这15天的旅程,是一次对自我的挑战,更是一场视觉与心灵的盛宴。我跨越山川湖海,见证了不同地域的万千风情。如果你也向往自由,渴望探索未知,那就勇敢出发吧!因为在路上,总有意想不到的美好在等待,希望2025年我们的祖国更加美好,人民的生活更加幸福美满!2025年我们一起加油.